




Do not create multi-accounts, you will be blocked!
Featured Replies
Recently Browsing 0
- No registered users viewing this page.
Latest Updated Files
-
- 56 Purchases
- 70 Comments
-
- 5 Downloads
- 0 Comments
-
- 4 Downloads
- 0 Comments
-
- 6 Downloads
- 0 Comments
-
- 21 Downloads
- 0 Comments
-
- 6 Downloads
- 0 Comments
-
- 30 Downloads
- 0 Comments
-
- 5 Downloads
- 0 Comments
-
- 10 Downloads
- 0 Comments
-
- 8 Downloads
- 0 Comments
-
- 7 Downloads
- 0 Comments
-
- 4 Downloads
- 0 Comments
-
- 11 Downloads
- 0 Comments
-
- 1 Downloads
- 0 Comments
-
- 7 Downloads
- 0 Comments
-
- 1 Downloads
- 0 Comments
-
- 3 Downloads
- 0 Comments
-
- 0 Purchases
- 0 Comments
-
- 62 Downloads
- 0 Comments
-
- 42 Downloads
- 0 Comments
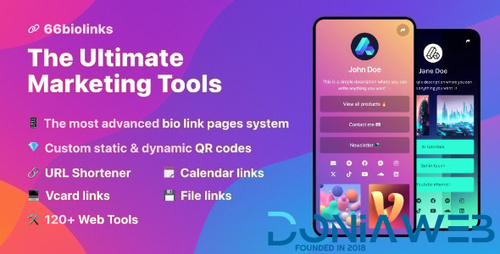
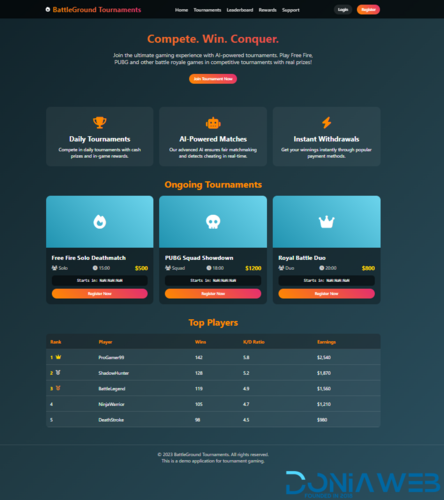



















.thumb.png.3f1bfda123fc58625543809c573aeff2.png)

Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.